Navigating Data Bias
February 8, 2022
In the late 1970s, our military changed its scheduled maintenance approach to an on-demand philosophy. This lowered the lifecycle costs of many kinds of assets (including land, sea and air vehicles), and it allowed for spending our tax dollars on smarter maintenance activities rather than unnecessary repairs.
As the program rolled out, the Air Force was initially skeptical when a young UCLA engineer informed them that the data they had sequestered for predictive failure analysis had a blind spot. That was how my first aerospace data science project began, and as we discuss below, blind spots are a common problem for many data science projects.
History Lesson for Today’s Data Science Projects with Blind Spots
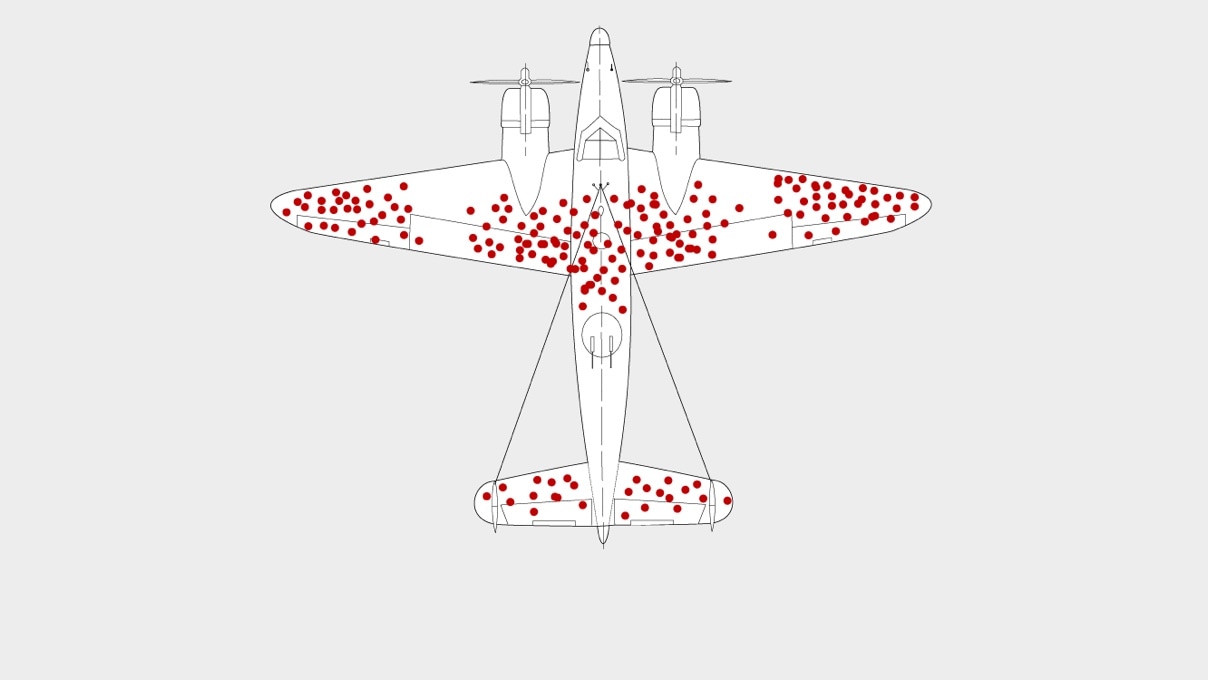
If you’re currently managing a data science project and suspect it might also have a blind spot, let’s first go back in history to World War II. A significant amount of ordinance was flown across the English Channel to Europe by the Allies. This campaign came at a tremendous cost in lives and equipment, and there was a strong desire to armor the aircraft to make them more resilient against enemy defenses.This case study is used to teach many data science students today about the WWII Allied statisticians who examined the aircraft that made it back from missions. The statisticians wanted to see where the bullet holes were on the planes to instruct aircraft designers to reinforce those areas.
Makes sense, right? Except for Abraham Wald, a Jewish mathematician who escaped Nazi advances into Romania and Europe to emigrate to the U.S. He served in the Statistical Research Group, a bunch of egg heads at Columbia University who used math to make the military better at everything from firing rockets to shooting down enemy fighters.
Wald had the epiphany that it was the planes that didn’t make it back that had the most important stories to tell. Their bullet holes were truly indicative of where armor should be added, rather than the ones that returned. This meant there was a survival bias in the data, which would lead to incorrect recommendations. (Here’s a great article if you want to read more about this.)
Past Relates to Current-Day Project
Now coming back to more recent times and a similar project…I was presented with data from turbine engines, airframes, and other major aircraft components that had been disassembled. I also reviewed the maintenance logs from normal maintenance modes. But I could not see the data of the equipment that had failed—badly, suddenly or catastrophically—or any of the information leading up to those events. Exceptional maintenance events, especially catastrophic failures, often didn’t make it into the normal log information. We only had the survivor cases. Attempts to integrate data from forensic sources proved difficult and could not be normalized, so we didn’t have a data set for proper inferences.To solve this, we had to get innovative about engineering new data sources. For example, in the area of turbine engines, we had to work with a manufacturer to coat key engine components with different trace elements. Then, we had to run the engines over time, drain the oil periodically, and measure the content of the trace materials in the oil, which would relate to the rate of wear of the specific components.
Next, we ran the test set under varying conditions to see how it impacted wear and what the precursors of failure looked like. Once sufficient data was acquired, we knew how an engine would age based on time and temperature. We even learned that certain modes of vibration would indicate an impending failure.
Determining If Your Data is Biased
Now to your data science project: Is your data survival biased? Has the culture and discipline around the measurements or metrics been unbiased? Will the data you plan to refine to make smarter decisions give you honest advice?Fortunately, there are specific industry sectors where this is a known problem, such as hedge funds, where only the funds that have survived are tracked and will likely give an upward bias to returns. Hedge fund companies take many steps to normalize their data so that they can clear any survivor bias.
There are other kinds of data bias too:
- Sample Selection Bias happens when certain data is excluded; for instance, the specifics around cases that didn’t go as expected or those with a great deal of anomaly edits.
- Look-Ahead Bias occurs when the test parameter uses information that was not available on the test date; for example, in a price-to-book ratio, calculations are made with a mix of real-time data and data that was not available until the end of a quarter.
- Time Period Bias results when a particular trend only happens to the data within a selected time period; this means the period was not statistically significant enough from which to gather a general inference. (Sometimes, external events such as interim government regulations can unknowingly skew the data).
Techniques to Test for Bias
The good news is, there are techniques that have been developed to test for the different types of data bias. Some use deep statistical tests, and some require testing algorithms against independent data sets to validate similar conclusions are achieved.The selected tests usually map to a particular kind of bias that is suspected. These bias tests are part-and-parcel of a properly-managed data science project. After all, you want to be sure you have “unbiased data” before you allow it to drive your critical business decisions.
If you have an internal data science team ready for a project launch, it’s prudent to take a close look at the data prior to commencing. If the data is not what you need, you may have to consider additional methods and costs for obtaining the required data.
Or, if an outside organization will deliver a turn-key data science driven process or a black-box machine learning algorithm, be sure they take the time to survey your data for bias early in the lifecycle of the project. This might have implications on the data size (storage costs) and the required computational strength to achieve the inferences you are looking for.
In the meantime, our sincere best wishes for you to make history with your data science venture!
Illustration: Martin Grandjean (vector), McGeddon (picture), Cameron Moll (concept), CC BY-SA 4.0, via Wikimedia Commons
About the author

BY
SHARE
Recent blog posts



{kind=link}

Stay in Touch
Keep your competitive edge – subscribe to our newsletter for updates on emerging software engineering, data and AI, and cloud technology trends.